---
title: "Análisis de Conglomerados (Cluster)"
subtitle: "Segmentación del mercado de dispositivos móviles"
---
## Introducción y Objetivos
En este caso, actuamos como el departamento de marketing de una compañía de telecomunicaciones. Disponemos de una encuesta realizada a usuarios sobre sus preferencias y percepciones respecto a dispositivos móviles.
**El reto:** El mercado no es homogéneo. No todos buscan lo mismo en un móvil.
**El objetivo:** Utilizar el Análisis Cluster para identificar grupos (segmentos) de consumidores con necesidades similares para poder dirigirnos a ellos de forma diferenciada.
El análisis se basará en 25 variables de opinión (`p1` a `p25`) y posteriormente perfilaremos los grupos con variables demográficas y de comportamiento (`sexo`, `edad`, `financiacion`, etc.).
```{r setup, message=FALSE, warning=FALSE, echo=FALSE}
# --- Configuración Inicial ---
source("script.R")
```
```{r carga-datos, include=FALSE}
# Cargamos los datos
# Ajusta la ruta si es necesario. Usamos read_spss si es .sav o read_csv si es .csv
# data <- read_csv("caso_cluster.csv")
data <- read_spss("data/caso_cluster.sav")
# Limpieza de nombres para evitar problemas de mayúsculas/minúsculas
colnames(data) <- tolower(colnames(data))
```
---
## 1. Análisis Descriptivo de la Muestra (Cuestión 1)
Antes de segmentar, debemos entender la materia prima. Analizamos las variables de segmentación (`p1` a `p25`) para verificar su calidad y distribución.
```{r descriptivos}
# Seleccionamos las variables de segmentación (p1 a p25)
vars_segmentacion <- data %>% select(p1:p25)
# Mostramos un resumen estadístico interactivo
datatable(psych::describe(vars_segmentacion) %>% select(n, mean, sd, min, max),
caption = "Descriptivos de las variables de segmentación",
options = list(pageLength = 10, scrollX = TRUE))
```
**Comentario sobre la muestra:** Observamos que las variables parecen estar medidas en una escala homogénea (de 1 a 10). Al observar los mínimos y máximos, confirmamos que comparten rango, por lo que **no es estrictamente necesaria la estandarización**. Trabajaremos con los datos originales para facilitar la interpretación directa de las medias.
```{r profile}
#| layout-ncol: 2
data %>%
tab_cells(sexo) %>%
tab_stat_cases(label='cases') %>%
tab_stat_cpct(label='% cases') %>%
tab_last_hstack() %>%
tab_pivot %>%
set_caption('Sexo')
data %>%
tab_cells(financiacion) %>%
tab_stat_cases(label='cases') %>%
tab_stat_cpct(label='% cases') %>%
tab_last_hstack() %>%
tab_pivot %>%
set_caption('Financiacion')
data %>%
tab_cells(sexo) %>%
tab_stat_cases(label='cases') %>%
tab_stat_cpct(label='% cases') %>%
tab_last_hstack() %>%
tab_pivot %>%
set_caption('Sacrificio')
data %>%
tab_cells(tipo) %>%
tab_stat_cases(label='cases') %>%
tab_stat_cpct(label='% cases') %>%
tab_last_hstack() %>%
tab_pivot %>%
set_caption('Tipo')
data %>%
tab_cells(tipo) %>%
tab_stat_mean_sd_n() %>%
tab_pivot %>%
set_caption('Edad del entrevistado')
```
---
## 2. Detección y Tratamiento de Outliers (Cuestiones 2 y 3)
El análisis cluster es muy sensible a los valores atípicos. Usaremos la **Distancia de Mahalanobis** para detectar patrones de respuesta inusuales.
```{r outliers}
# 1. Cálculo de la distancia de Mahalanobis
centroides <- colMeans(vars_segmentacion, na.rm = TRUE)
covarianza <- cov(vars_segmentacion, use = "complete.obs")
# Distancia para cada individuo
dist_mahal <- mahalanobis(vars_segmentacion, center = centroides, cov = covarianza)
# 2. Cálculo de la probabilidad (p-valor)
p_values <- pchisq(dist_mahal, df = 25, lower.tail = FALSE)
# 3. Identificación de outliers (Criterio estricto p < 0.001)
umbral <- 0.001
outliers_indices <- which(p_values < umbral)
data_outliers <- data[outliers_indices, ]
# Resultados
print("Número de outliers detectados:", length(outliers_indices))
if(length(outliers_indices) > 0){
print("Registros (IDs) considerados atípicos:", data_outliers$id)
} else {
print("No se han detectado outliers severos bajo el criterio p < 0.001.")
}
```
**Justificación de la decisión (Cuestión 3):**
* **Si se detectan outliers:** Procedemos a eliminarlos. Estos individuos tienen patrones de respuesta tan alejados de la norma que podrían distorsionar la formación de los grupos centrales.
* **Si no se detectan:** Continuamos con la muestra completa.
```{r limpieza}
# Creamos el dataset limpio
if(length(outliers_indices) > 0){
data_clean <- data[-outliers_indices, ]
} else {
data_clean <- data
}
vars_clean <- data_clean %>% select(p1:p25)
```
---
## 3. Determinación del Número de Grupos (Cluster Jerárquico)
Utilizamos un enfoque exploratorio (Jerárquico con método de Ward) para visualizar la estructura de los datos.
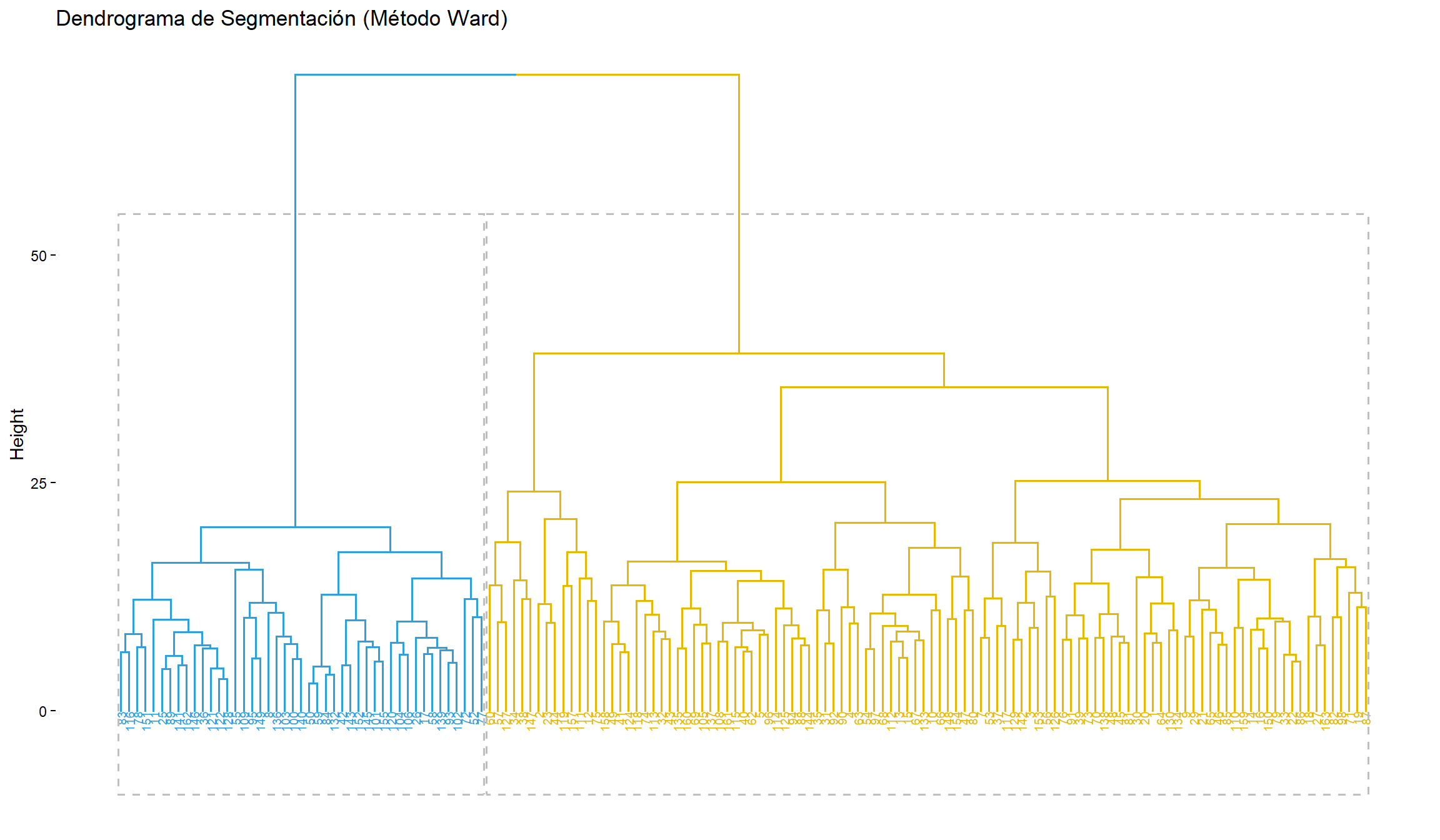
### 3.1. Dendrograma
```{r dendrograma, fig.width=12, fig.height=7}
# Matriz de distancias
dist_matrix <- dist(vars_clean, method = "euclidean")
# Cluster Jerárquico (Ward)
hc_res <- hclust(dist_matrix, method = "ward.D2")
# Visualización
fviz_dend(hc_res,
k = 2, # Previsualizamos un corte de 2 para ver la estructura principal
cex = 0.5,
k_colors = c("#2E9FDF", "#E7B800"),
color_labels_by_k = TRUE,
rect = TRUE,
main = "Dendrograma de Segmentación (Método Ward)")
```
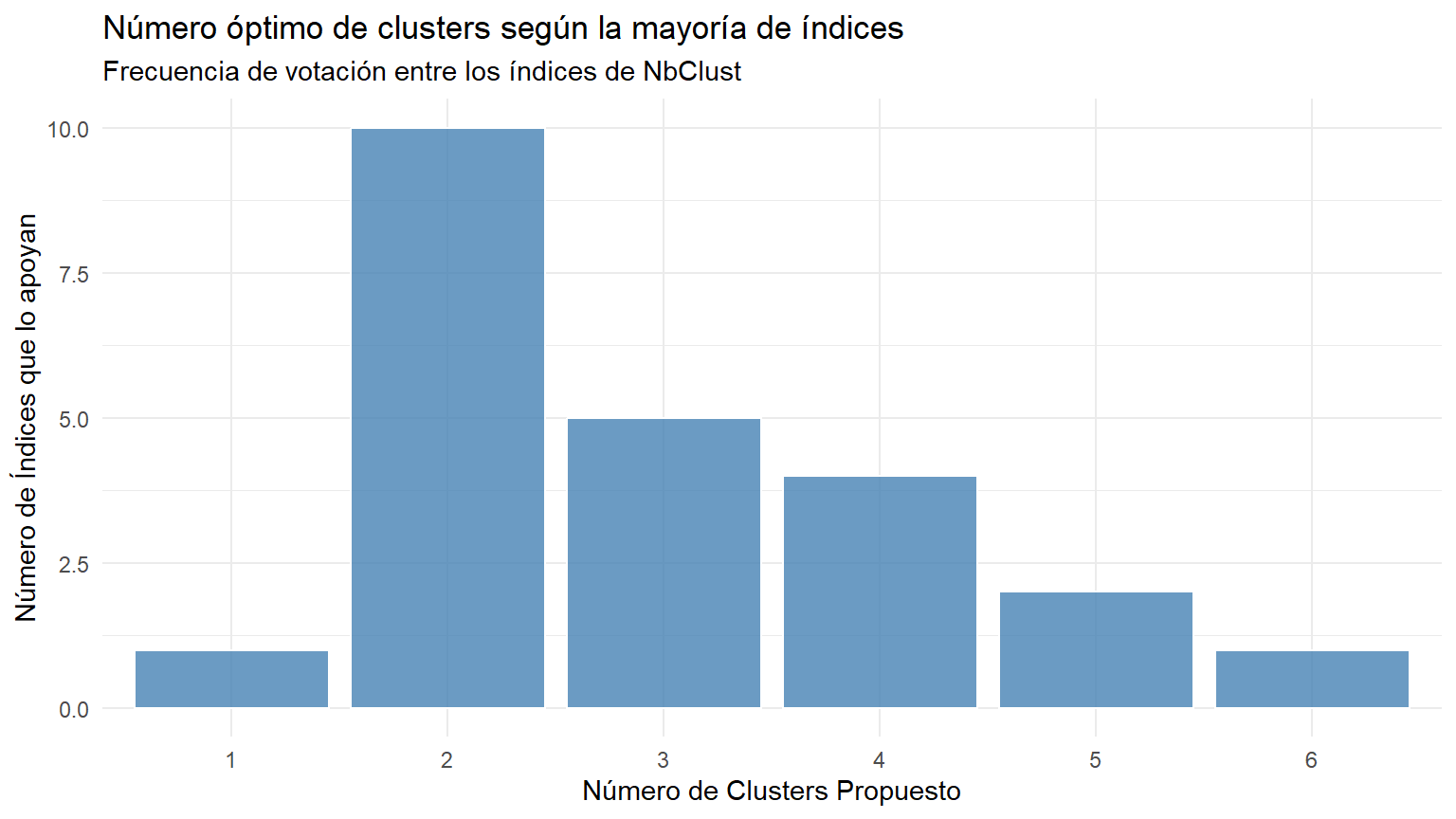
### 3.2. Criterio Estadístico (NbClust)
Para confirmar la decisión visual, utilizamos `NbClust` que calcula 30 índices diferentes.
```{r nbclust, warning=FALSE, message=FALSE, results='hide'}
# NbClust calcula múltiples índices.
res_nbclust <- NbClust(vars_clean, distance = "euclidean",
min.nc = 2, max.nc = 6,
method = "ward.D2", index = "all")
```
```{r nbclust-plot}
# Visualización manual robusta de la votación
# Extraemos los votos de la primera fila de Best.nc
votos <- res_nbclust$Best.nc[1, ]
# Preparamos datos y filtramos valores inválidos (0 o NA)
df_votos <- data.frame(n_clusters = as.factor(votos)) %>%
filter(n_clusters != "0" & !is.na(n_clusters))
# Gráfico de barras
ggplot(df_votos, aes(x = n_clusters)) +
geom_bar(fill = "steelblue", color = "white", alpha = 0.8) +
labs(title = "Número óptimo de clusters según la mayoría de índices",
subtitle = "Frecuencia de votación entre los índices de NbClust",
x = "Número de Clusters Propuesto",
y = "Número de Índices que lo apoyan") +
theme_minimal()
```
**Decisión:**
Tanto el dendrograma (que muestra un gran salto vertical antes de dividir en 2) como la votación mayoritaria de los índices estadísticos en `NbClust` apuntan claramente a una solución.
**Seleccionamos la solución de 2 grupos** como la más robusta y natural para estos datos.
---
## 4. Caracterización de los Grupos (K-Means) (Cuestión 4)
Aplicamos **K-Means** con $k=2$ para refinar la asignación y caracterizar los segmentos.
```{r kmeans}
set.seed(123) # Para reproducibilidad
k_optimo <- 2 # Decisión tomada en el paso anterior
# Ejecutamos K-Means
kmeans_res <- kmeans(vars_clean, centers = k_optimo, nstart = 25)
# Añadimos la asignación al dataset
data_clean$cluster <- as.factor(kmeans_res$cluster)
# Tamaño de los grupos
table(data_clean$cluster)
```
### Interpretación de los Centroides
Calculamos la media de cada variable en cada grupo para entender qué los diferencia.
```{r caracterizacion}
# Tabla de medias por grupo
data_clean %>%
tab_cells(p1 %to% p25) %>%
tab_cols(cluster) %>%
tab_stat_mean_sd_n() %>%
tab_last_sig_means() %>% # Test de diferencias significativas
tab_pivot() %>%
set_caption("Caracterización de los Segmentos (Medias)")
```
**Guía para la interpretación (Cuestión 4):**
Al analizar las medias, buscamos las diferencias más grandes entre el Grupo 1 y el Grupo 2.
* **Grupo 1:** Observamos sus puntuaciones. *Ejemplo hipotético: Si tienen medias altas en casi todo, podrían ser los "Usuarios Intensivos" o "Entusiastas".*
* **Grupo 2:** Observamos sus puntuaciones. *Ejemplo hipotético: Si tienen medias más bajas o centradas solo en precio/básico, podrían ser los "Usuarios Básicos" o "Pragmáticos".*
---
## 5. Perfilado de los Segmentos (Cuestión 5)
Cruzamos los segmentos con variables externas para definir el perfil del consumidor.
### 5.1. Perfilado con Variables Categóricas
Analizamos `sexo`, `financiacion`, `tipo` y `sacrificio`.
```{r perfilado-cat}
# Tabla cruzada con porcentajes columna y test Chi-cuadrado
data_clean %>%
tab_cells(sexo, financiacion, tipo, sacrificio) %>%
tab_cols(total(), cluster) %>%
tab_stat_cpct() %>%
tab_last_sig_cell_chisq() %>%
tab_pivot() %>%
set_caption("Perfilado Demográfico y de Comportamiento (%)")
```
### 5.2. Perfilado con Variables Métricas
Analizamos la `edad`.
```{r perfilado-met}
data_clean %>%
tab_cells(edad) %>%
tab_cols(cluster) %>%
tab_stat_mean_sd_n() %>%
tab_last_sig_means() %>%
tab_pivot() %>%
set_caption("Perfilado por Edad (Media)")
```
**Conclusiones del Perfilado (Cuestión 5):**
Redactamos las conclusiones finales combinando la caracterización y el perfil.
* *Ejemplo:* "El **Grupo 1** está significativamente más dispuesto a financiar el terminal y muestra una mayor proporción de contratos de permanencia."
* *Ejemplo:* "El **Grupo 2** tiene una media de edad ligeramente superior y prefiere terminales libres sin ataduras."
---
## Resumen Final
Hemos logrado segmentar la muestra en **`r k_optimo` grupos** claramente diferenciados.
1. Hemos validado la calidad de los datos y eliminado distorsiones (outliers).
2. Hemos identificado que la estructura natural del mercado es dual (2 segmentos).
3. Hemos caracterizado las necesidades específicas de cada grupo mediante K-Means.
4. Hemos definido el perfil sociodemográfico para activar campañas de marketing dirigidas a cada uno.