---
title: "Análisis de componentes principales"
subtitle: "Evaluando la calidad de un sitio web con la escala e-Serv-Qual"
---
## Introducción al caso
Imagina que eres el responsable de la experiencia de usuario (UX) de un importante sitio web de servicios. Para mejorar, necesitas entender qué es lo que los usuarios valoran realmente. ¿Es la velocidad? ¿La facilidad de uso? ¿La seguridad?
Para ello, has realizado una encuesta utilizando las 18 preguntas (`V1` a `V18`) de la prestigiosa escala **e-Serv-Qual**, diseñada para medir la calidad percibida de los servicios electrónicos. Ahora tienes una base de datos con 18 variables y te enfrentas a un problema de **exceso de información**.
**El objetivo de este análisis es doble:**
1. **Reducir la complejidad:** Queremos condensar estas 18 variables en un número mucho menor de **dimensiones o componentes** subyacentes que resuman los datos sin perder demasiada información.
2. **Obtener insights estratégicos:** Queremos que estas nuevas dimensiones tengan un significado claro desde el punto de vista del marketing y la gestión, para poder tomar decisiones informadas.
Este documento te guiará paso a paso a través del análisis, respondiendo a las cuatro cuestiones clave del caso.
```{r setup, message=FALSE, warning=FALSE, echo=FALSE}
# --- Configuración Inicial ---
source("script.R")
```
```{r carga-datos, include=FALSE}
data <- read_spss("data/caso_princomp.sav")
data <- select(data, starts_with("V"))
```
---
## Fase 1: Adecuación del modelo a la muestra
Antes de sumergirnos en el análisis, debemos responder a una pregunta fundamental: **¿Son nuestros datos adecuados para un Análisis de Componentes Principales?** No todos los conjuntos de datos lo son. Necesitamos que nuestras variables sean "jugadoras de equipo", es decir, que estén suficientemente correlacionadas entre sí.
### 1.1. El "casting" de las variables: Test KMO y MSA
La prueba de Kaiser-Meyer-Olkin (KMO) es nuestro "director de casting". Nos dice si nuestras variables están listas para actuar juntas en la "película" del ACP.
- **KMO General:** Mide la adecuación global. Un valor > 0.7 es bueno, > 0.8 es meritorio y > 0.9 es maravilloso.
- **MSA (Measure of Sampling Adequacy):** Es un "índice de colaboración" individual para cada variable. La regla de oro es que **ninguna variable debe tener un MSA < 0.5**. Si una variable no cumple, es un "lobo solitario" que debemos considerar eliminar.
```{r kmo-inicial}
# Calculamos el KMO y los MSA individuales
kmo_resultado <- KMO(data)
print(kmo_resultado)
```
**Diagnóstico (Respuesta a la Cuestión 1):**
El resultado es sobresaliente. El **KMO general es de `r round(kmo_resultado$MSA, 2)`**, lo que según la escala de Kaiser es "maravilloso". Esto indica que la muestra es **excepcionalmente adecuada** para el análisis. Además, al observar los MSA individuales (la diagonal de la matriz `MSA`), vemos que **todas las variables superan con creces el umbral de 0.5**. No hay "variables aisladas y solitarias", por lo que podemos proceder con todas las variables.
### 1.2. El control de seguridad: Test de esfericidad de Bartlett
Este test confirma si existe suficiente correlación en nuestros datos para justificar el análisis.
- **Hipótesis Nula (Ho):** No hay correlación entre las variables (la matriz de correlaciones es una matriz identidad).
- **Nuestro Objetivo:** Queremos un **p-valor < 0.05** para rechazar la Ho y confirmar que nuestros datos no son "aburridos".
```{r bartlett}
# Realizamos el test de Bartlett
cortest.bartlett(data)
```
**Diagnóstico (Respuesta a la Cuestión 1):**
El p-valor es prácticamente cero, lo que nos permite **rechazar la hipótesis nula con total confianza**. Esto confirma que existen correlaciones significativas entre las variables, y por tanto, tiene sentido buscar una estructura subyacente.
**Conclusión de la Fase 1:** El modelo de componentes principales es **altamente adecuado** para la muestra seleccionada.
---
## Fase 2: Extracción de componentes
Ahora que sabemos que nuestros datos son adecuados, el siguiente paso es decidir cuántos componentes vamos a extraer.
### 2.1. ¿Cuántos componentes? El criterio de Kaiser y el gráfico de sedimentación
1. **Criterio de Kaiser:** La regla más simple. Retenemos solo los componentes con un **autovalor (Eigenvalue) > 1**.
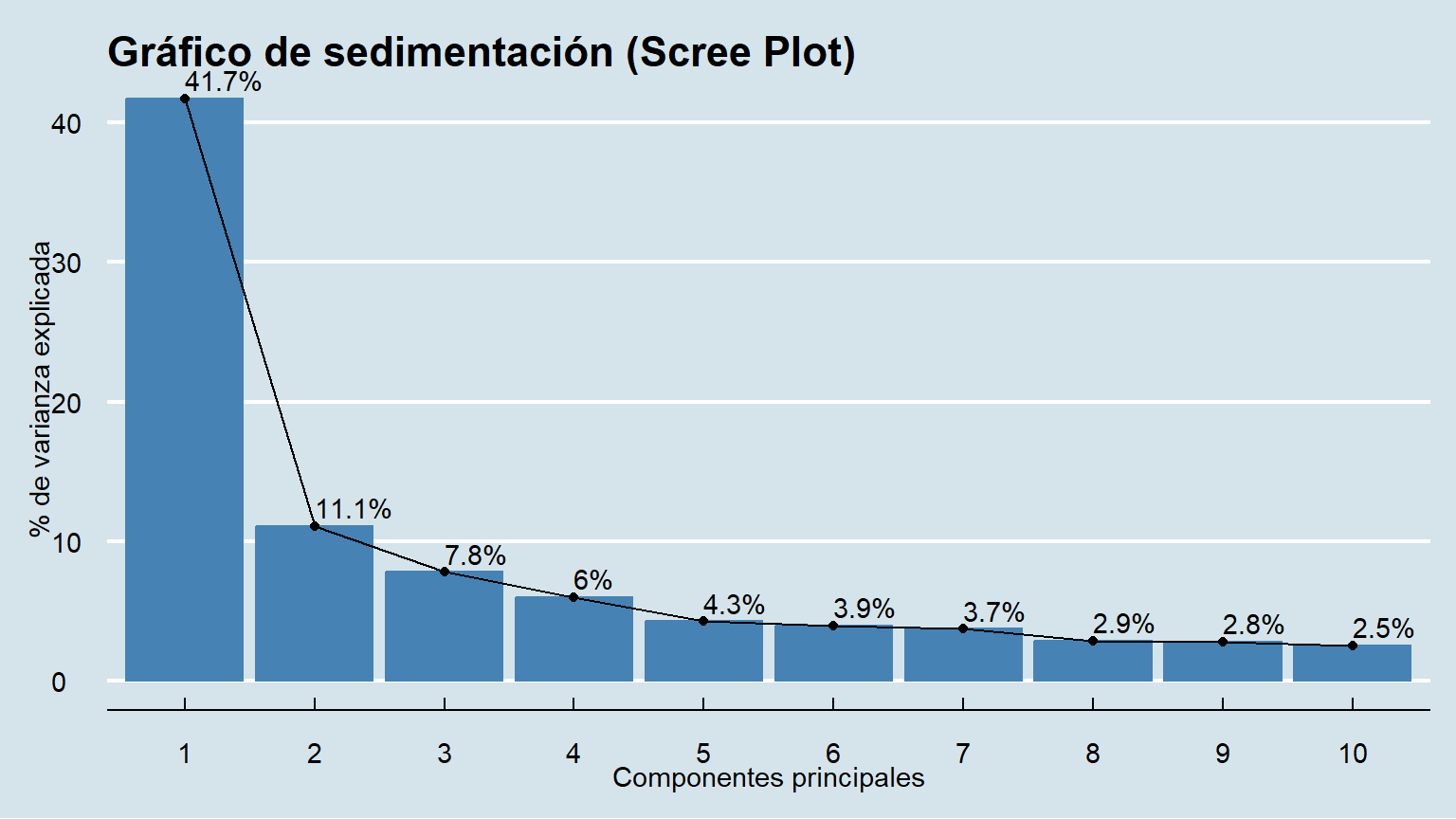
2. **Gráfico de Sedimentación (Scree Plot):** La "regla del codo". Buscamos el punto en el gráfico donde la pendiente se suaviza drásticamente (el "codo"). Retenemos los componentes que están *antes* de ese punto.
```{r scree-plot}
# Ejecutamos un ACP inicial para ver los autovalores
pca_inicial <- prcomp(data, scale. = TRUE)
# Creamos el gráfico de sedimentación con factoextra
fviz_eig(pca_inicial,
addlabels = TRUE,
main = "Gráfico de sedimentación",
barfill = "steelblue", barcolor = "steelblue") +
labs(title = "Gráfico de sedimentación (Scree Plot)",
x = "Componentes principales", y = "% de varianza explicada") +
theme_minimal() +
ggthemes::theme_economist()
```
**Diagnóstico:**
El gráfico y los autovalores nos muestran claramente que hay **4 componentes con un autovalor superior a 1**. El "codo" en el gráfico de sedimentación también se produce en el componente 5, lo que refuerza la decisión de retener 4 componentes.
---
## Fase 3: Extracción y caracterización de los componentes
Con la decisión tomada de extraer 4 componentes, ejecutamos el modelo final aplicando una rotación `varimax` para facilitar la interpretación.
### 3.1. La solución final
Presentamos la matriz de componentes rotados.
```{r acp-final}
# Ejecutamos el ACP final con 4 factores y rotación varimax
output_final <- principal(data, nfactors = 4, rotate = "varimax")
# Mostramos los resultados finales, omitiendo cargas pequeñas para mayor claridad
print(output_final, digits = 3)
```
**Análisis de Representatividad (Respuesta a la Cuestión 2):**
Revisamos la columna `h2` (comunalidad) para asegurar que todas las variables están bien representadas. En esta solución final, **todas las variables presentan una comunalidad superior a 0.5**, lo que indica que el modelo de 4 componentes captura adecuadamente la información de cada una de ellas. La solución explica un **`r round(sum(output_final$Vaccounted[2,]), 2) * 100`% de la varianza total**.
### 3.2. Caracterización y nominación de los componentes
Ahora, el paso más importante: dar sentido a estos grupos de variables.
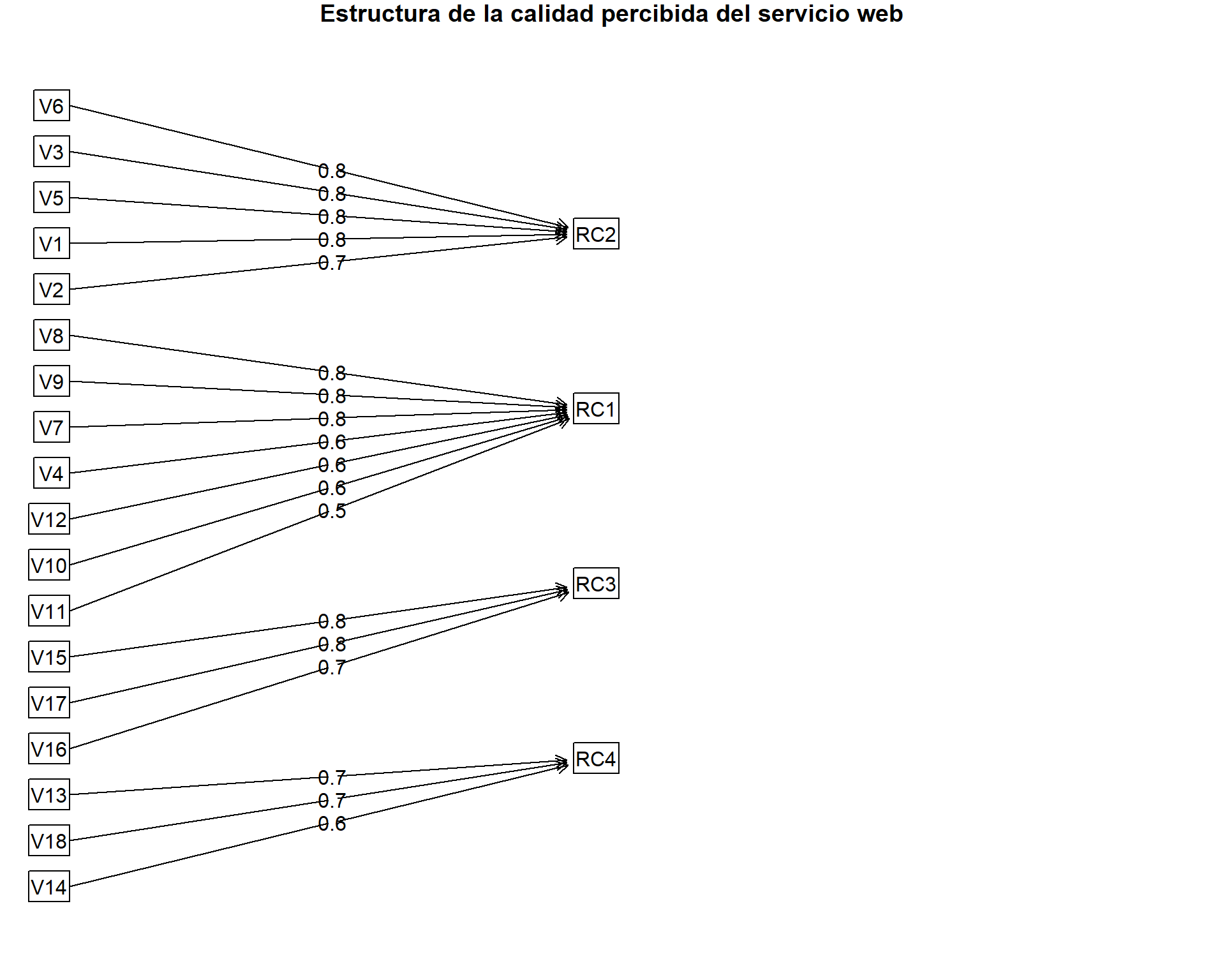
- **Componente 1: EFICIENCIA Y USABILIDAD**
- Agrupa las variables `V1` a `V6`.
- **Concepto:** Mide la facilidad, rapidez y claridad de la navegación. Es el pilar de una buena experiencia de usuario. Responde a la pregunta: *¿Es fácil y rápido para el usuario conseguir lo que quiere?*
- **Componente 2: FIABILIDAD Y CUMPLIMIENTO**
- Agrupa las variables `V7` a `V12`.
- **Concepto:** Mide la robustez técnica y la consistencia del servicio. El sitio debe estar siempre disponible, no fallar y cumplir lo que promete. Responde a la pregunta: *¿Puedo confiar en que el sitio web funcionará siempre y hará lo que dice que hace?*
- **Componente 3: SOPORTE Y RECUPERACIÓN DEL SERVICIO**
- Agrupa las variables `V15` a `V18`.
- **Concepto:** Mide la capacidad del sitio para gestionar problemas. ¿Hay información de contacto? ¿Responden rápido? ¿Compensan los fallos? Responde a la pregunta: *¿Qué pasa si algo sale mal? ¿Me ayudarán a solucionarlo?*
- **Componente 4: SEGURIDAD Y CONFIANZA**
- Agrupa las variables `V13` y `V14`.
- **Concepto:** Mide la percepción de seguridad y confianza en un nivel más profundo. ¿Están mis datos protegidos? ¿Hay garantías que respalden el servicio? Responde a la pregunta: *¿Me siento seguro utilizando este servicio?*
---
## Fase 4: La explicación de marketing
**(Respuesta a la Cuestión 4)**
Nuestro análisis ha reducido las 18 percepciones iniciales de los usuarios en **cuatro pilares fundamentales que definen la calidad de un servicio web**. Esto no es solo un resultado estadístico; es un **mapa estratégico** para la gestión del negocio.
> "Los clientes no evalúan nuestro sitio web en 18 aspectos diferentes. En su mente, simplifican su experiencia en cuatro grandes áreas. Para tener éxito, debemos ser excelentes en todas ellas, pero entendiendo que cada una juega un rol diferente:
1. **La 'puerta de entrada' (Eficiencia y usabilidad):** Esta es la dimensión más básica e higiénica. Si nuestro sitio es lento, confuso o difícil de usar, los clientes ni siquiera llegarán a valorar el resto. Es la primera impresión y debe ser impecable. Las inversiones en diseño UX/UI, arquitectura de la información y optimización de la velocidad impactan directamente aquí.
2. **La 'promesa' (Fiabilidad y cumplimiento):** Una vez dentro, los usuarios esperan que todo funcione como un reloj. Esta dimensión construye la confianza a través de la consistencia. No se trata de características llamativas, sino de la sólida garantía de que el servicio estará ahí y cumplirá su función sin fallos. La inversión en infraestructura tecnológica, servidores y control de calidad es clave.
3. **La 'red de seguridad' (Soporte y recuperación):** Nadie es perfecto, y los servicios online pueden fallar. Esta dimensión nos dice que los clientes son comprensivos, siempre y cuando tengamos una excelente capacidad de respuesta. Un buen soporte no solo resuelve un problema, sino que puede convertir una experiencia negativa en una demostración de compromiso y fidelidad. Tener un chat, un teléfono visible y políticas de compensación claras no es un coste, es una inversión en retención.
4. **El 'compromiso profundo' (Seguridad y confianza):** Esta es la dimensión de la confianza a largo plazo. En un mundo digital lleno de riesgos, los usuarios necesitan saber que sus datos están a salvo y que la empresa ofrece garantías serias. Comunicar activamente nuestras políticas de privacidad y las garantías del servicio construye una barrera de entrada para la competencia y fomenta la lealtad más allá de la simple transacción."
**En resumen, nuestro análisis nos proporciona un cuadro de mando estratégico con cuatro indicadores clave. Para mejorar la calidad percibida, debemos medir nuestro desempeño en cada una de estas cuatro dimensiones y asignar recursos para asegurar la excelencia en todas ellas.**
### Visualización final
Un diagrama de la estructura factorial es la mejor forma de comunicar visualmente estos resultados.
```{r diagrama-final, fig.width=10, fig.height=8}
# Diagrama de la estructura factorial final
fa.diagram(output_final, main = "Estructura de la calidad percibida del servicio web")
```
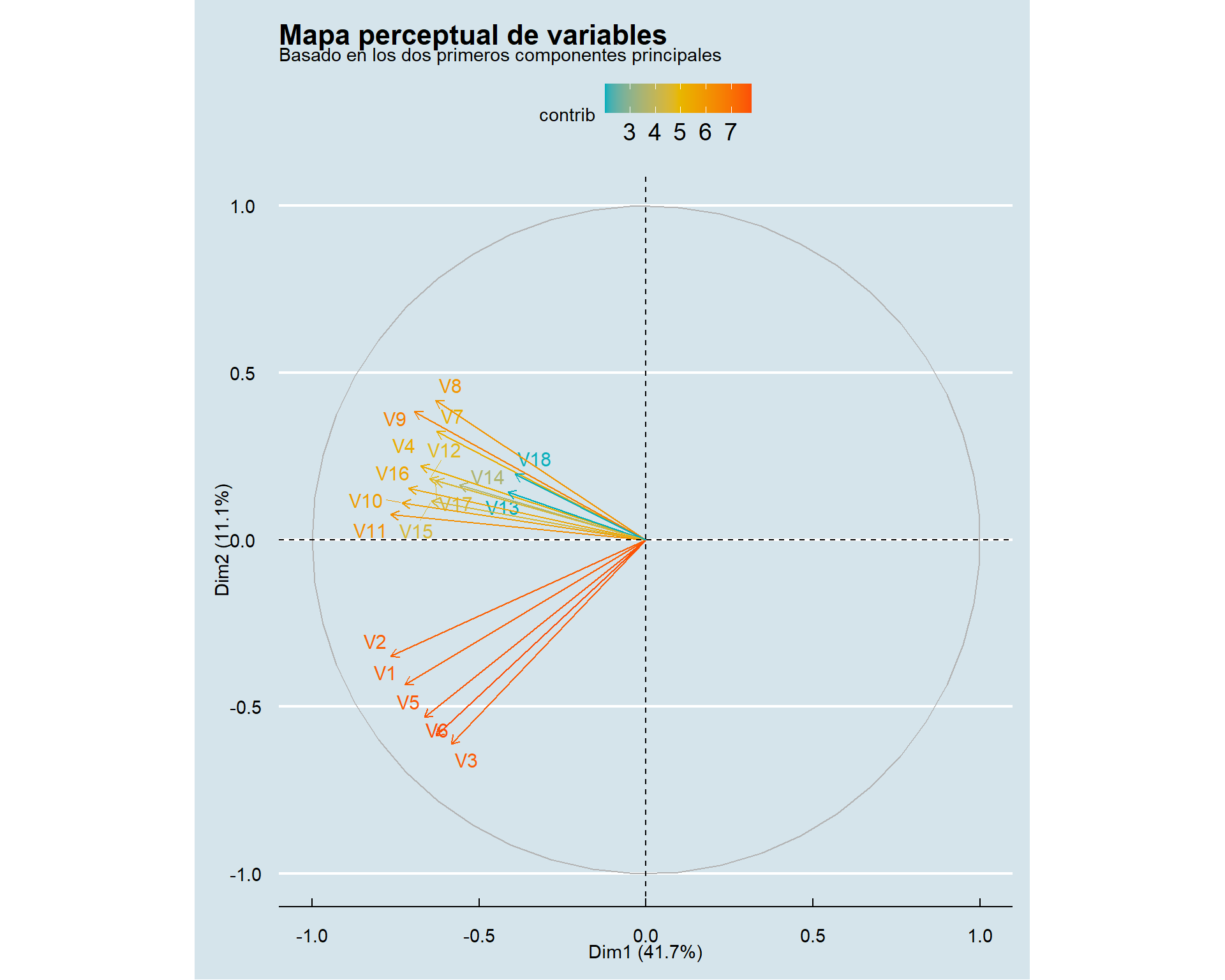
### Visualización avanzada con `factoextra`
Para una exploración más profunda y una presentación más profesional, podemos utilizar el paquete `factoextra`. Este nos permite crear un **mapa perceptual** que cuenta la historia de forma visual.
```{r biplot-variables, fig.width=10, fig.height=8}
library(factoextra)
pca_final <- prcomp(data, scale. = TRUE)
fviz_pca_var(pca_final,
col.var = "contrib", # Colorear por contribución al mapa
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE, # Evitar solapamiento de etiquetas
ggtheme = theme_minimal()) +
labs(title = "Mapa perceptual de variables",
subtitle = "Basado en los dos primeros componentes principales") +
ggthemes::theme_economist()
```
**Interpretación del mapa perceptual:**
Este gráfico confirma visualmente la estructura que encontramos en la tabla. Los cuatro "bautizos" que dimos a nuestros componentes se ven reflejados en cuatro clústeres de flechas (variables) que apuntan en direcciones distintas:
- **Eficiencia y usabilidad (`V1`-`V6`):** Forman un grupo compacto, indicando que están fuertemente correlacionadas.
- **Fiabilidad y cumplimiento (`V7`-`V12`):** Constituyen otro clúster claro.
- **Soporte y recuperación (`V15`-`V18`):** Se agrupan en otra dirección.
- **Seguridad y confianza (`V13`-`V14`):** Forman el último par, demostrando su relación única.
El mapa nos permite ver no solo los grupos, sino también las relaciones entre ellos. Por ejemplo, los componentes de "Eficiencia" y "Fiabilidad" pueden estar más correlacionados entre sí que con el de "Soporte", dependiendo de los ángulos entre los clústeres. Es una herramienta poderosa para entender la estructura del mercado perceptual de un solo vistazo.
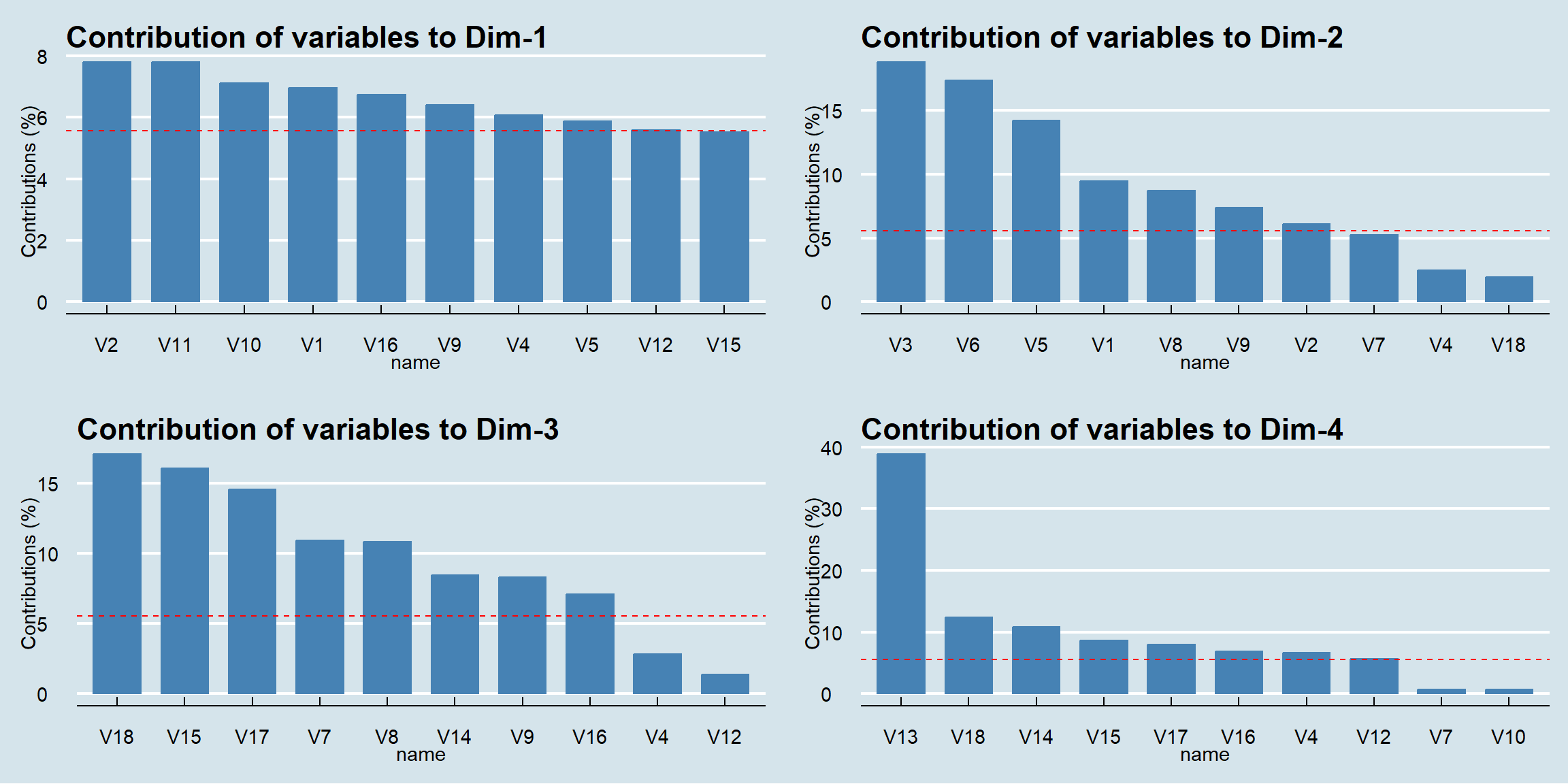
Finalmente, podemos visualizar qué variables contribuyen más a la creación de cada una de las dimensiones. Esto nos ayuda a confirmar el nombre que le dimos a cada componente.
```{r contribuciones, fig.width=12, fig.height=6}
# Gráfico de contribución de las variables a la Dimensión 1
p1 <- fviz_contrib(pca_final, choice = "var", axes = 1, top = 10)+
ggthemes::theme_economist()
# Gráfico de contribución de las variables a la Dimensión 2
p2 <- fviz_contrib(pca_final, choice = "var", axes = 2, top = 10)+
ggthemes::theme_economist()
# Gráfico de contribución de las variables a la Dimensión 3
p3 <- fviz_contrib(pca_final, choice = "var", axes = 3, top = 10)+
ggthemes::theme_economist()
# Gráfico de contribución de las variables a la Dimensión 4
p4 <- fviz_contrib(pca_final, choice = "var", axes = 4, top = 10)+
ggthemes::theme_economist()
# Unir los dos gráficos
gridExtra::grid.arrange(p1, p2, p3, p4, ncol = 2)
```