Code
# --- Configuración Inicial ---
source("script.R")Dos simples e intuitivos supuestos
Cargamos los paquetes necesarios y los datos.
ca: para la realización del análisis de correspondenciasfactoextra:para la creación de gráficos específicos del análisisggplot2: básico general de gráficos# --- Configuración Inicial ---
source("script.R")Objetivo: Aplicar el análisis de correspondencias para transformar una tabla de datos en un mapa perceptual estratégico y contar una historia de marketing coherente.
Instrucciones 1. Importamos la tabla, introduciendo la misma como tal. 2. Ejecutamos el análisis de correspondencias. 3. Interpretamos el mapa perceptual respondiendo a las preguntas de negocio planteadas en cada caso.
Una consultora de investigación de mercados ha realizado un estudio de asociación de imagen de marca para cuatro fabricantes de smartphones. Se preguntó a una muestra de 500 consumidores qué atributo asociaban más fuertemente con cada marca. Los resultados se resumen en la siguiente tabla de contingencia.
Preguntas de negocio: 1. ¿Cómo se posicionan estas cuatro marcas en la mente del consumidor? 2. ¿Cuáles son los principales ejes de competencia en este mercado? 3. ¿Qué marcas compiten más directamente entre sí?
Esta tabla está diseñada para ser extremadamente clara. Las asociaciones son muy fuertes y polarizadas.
# --- CASO 1: SMARTPHONES ---
# Crear la tabla de contingencia
# Datos diseñados para tener una estructura muy clara
datos_smartphones <- matrix(
c(
# Atributos -> Diseño, Calidad/Precio, Innovación, Precio Bajo
150,
10,
20,
5, # Apple
15,
120,
10,
10, # Xiaomi
30,
15,
140,
20, # Samsung
5,
15,
5,
160 # Alcatel
),
nrow = 4,
byrow = TRUE
)
# Asignar nombres a filas y columnas
rownames(datos_smartphones) <- c("Apple", "Xiaomi", "Samsung", "Alcatel")
colnames(datos_smartphones) <- c(
"Diseño_Premium",
"Calidad_Precio",
"Innovacion_Tecnologica",
"Precio_Bajo"
)
# Convertir a tabla para visualizar
tabla_smartphones <- as.table(datos_smartphones)
knitr::asis_output("#### Tabla de contingencia")print(tabla_smartphones) Diseño_Premium Calidad_Precio Innovacion_Tecnologica Precio_Bajo
Apple 150 10 20 5
Xiaomi 15 120 10 10
Samsung 30 15 140 20
Alcatel 5 15 5 160knitr::asis_output("#### Prueba ChiSquare")chisq=chisq.test(tabla_smartphones)
chisq
Pearson's Chi-squared test
data: tabla_smartphones
X-squared = 1112, df = 9, p-value < 2.2e-16knitr::asis_output("#### Residuos estandarizados ajustados")chisq$stdres Diseño_Premium Calidad_Precio Innovacion_Tecnologica Precio_Bajo
Apple 18.947957 -6.283256 -4.853124 -8.542070
Xiaomi -5.573437 18.820185 -5.757174 -6.423575
Samsung -4.831537 -5.958801 17.527363 -6.470185
Alcatel -8.716060 -5.254831 -7.842813 21.266263knitr::asis_output("#### Análisis de correspondencias")# Realizar el análisis de correspondencias
ca_smartphones <- ca(tabla_smartphones)
# Resumen del análisis (clave para interpretar la inercia)
print(summary(ca_smartphones))$scree
values values2 values3
[1,] 1 0.6478187 42.52806 42.52806
[2,] 2 0.4857057 31.88565 74.41371
[3,] 3 0.3897493 25.58629 100.00000
$rows
name mass qlt inr k=1 cor ctr k=2 cor ctr
1 Appl 253 590 244 -851 495 284 -373 95 73
2 Xiam 212 1000 251 -5 0 0 1342 1000 788
3 Smsn 281 256 200 -391 141 66 -353 115 72
4 Alct 253 976 305 1289 905 650 -361 71 68
$columns
name mass qlt inr k=1 cor ctr k=2 cor ctr
1 Dñ_P 274 604 239 -827 514 289 -346 90 67
2 Cl_P 219 1000 249 34 1 0 1315 999 780
3 In_T 240 262 212 -465 160 80 -371 102 68
4 Pr_B 267 985 300 1237 895 631 -392 90 84
attr(,"class")
[1] "summary.ca"# Visualización del mapa perceptual
# Usamos factoextra para un gráfico más estético y claro
knitr::asis_output("#### Mapa perceptual")fviz_ca_biplot(
ca_smartphones,
repel = TRUE, # Evita que las etiquetas se solapen
title = "Mapa perceptual del mercado de smartphones"
) +
labs(subtitle = "Basado en asociaciones de imagen de marca") +
ggthemes::theme_economist() +
coord_cartesian(ylim = c(-0.6, 0.8)) # Ajusta los límites del eje Y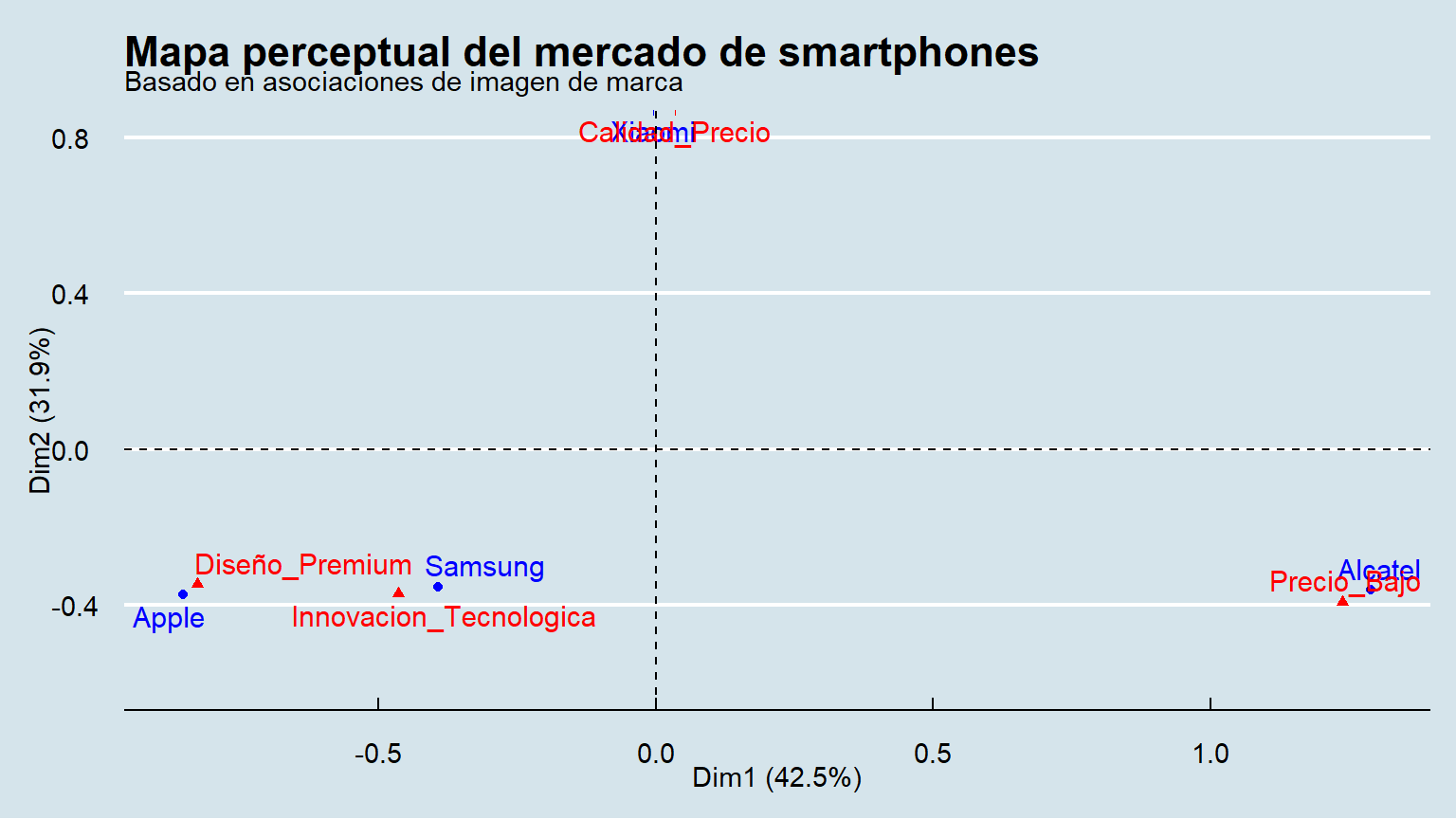
Análisis de la inercia: El resumen del análisis mostrará que las dos primeras dimensiones explican un porcentaje altísimo de la inercia total (probablemente >95%). Esto significa que nuestro mapa 2D es una representación casi perfecta y muy fiable de la realidad de los datos.
Interpretación de los ejes (dimensiones):
Precio_Bajo y en el otro Diseño_Premium e Innovacion_Tecnologica. Este eje representa claramente la principal tensión del mercado: “Eje de valor vs. premium”. A la izquierda están las marcas de bajo coste y a la derecha las de alto valor añadido.Innovacion_Tecnologica (Samsung) y en la inferior Diseño_Premium (Apple). Este eje podría interpretarse como “Eje de diferenciación premium: tecnología vs. estatus/diseño”.Posicionamiento y competencia (contando la historia):
Diseño_Premium es casi exclusiva. No compite directamente con nadie en su nicho.Innovacion_Tecnologica.Calidad_Precio. Ocupa un espacio intermedio en el eje premium.Precio_Bajo). Su propuesta es puramente funcional y económica.Conclusión del caso 1: El mercado está muy estructurado y cada marca tiene un posicionamiento muy claro y bien defendido. La competencia directa es limitada, ya que cada una opera en un cuadrante bien definido.
Una agencia de branding quiere entender las personalidades de marca en el sector automotriz. En lugar de atributos funcionales, han medido la asociación de seis marcas con arquetipos de consumidor o valores de estilo de vida.
Preguntas de negocio: 1. ¿Qué personalidades de marca (arquetipos) dominan el sector? 2. ¿Existen “océanos azules” o espacios de posicionamiento desocupados? 3. ¿Cómo se diferencian marcas que, a priori, podrían parecer similares (ej. BMW y Mercedes)?
Esta tabla es más compleja. Las asociaciones son más sutiles y hay más “solapamiento” entre marcas.
# --- CASO 2: MARCAS DE COCHES (COMPLEJO) ---
# Crear la tabla de contingencia
# Datos diseñados con más matices y solapamientos
datos_coches <- matrix(
c(
# Atributos -> Seguridad, Aventura, Lujo, Rendimiento, Fiabilidad, Innovación
140,
10,
40,
20,
50,
30, # Volvo
10,
150,
15,
30,
10,
10, # Jeep
40,
10,
130,
110,
20,
50, # BMW
50,
5,
140,
60,
40,
70, # Mercedes
20,
10,
10,
10,
160,
20, # Toyota
30,
10,
60,
80,
30,
150 # Tesla
),
nrow = 6,
byrow = TRUE
)
# Asignar nombres
rownames(datos_coches) <- c(
"Volvo",
"Jeep",
"BMW",
"Mercedes",
"Toyota",
"Tesla"
)
colnames(datos_coches) <- c(
"Seguridad_Familiar",
"Espiritu_Aventurero",
"Lujo_Clasico",
"Rendimiento_Deportivo",
"Fiabilidad_Practica",
"Innovacion_Sostenible"
)
# Convertir a tabla
tabla_coches <- as.table(datos_coches)
knitr::asis_output("#### Tabla de contingencia")print(tabla_smartphones) Diseño_Premium Calidad_Precio Innovacion_Tecnologica Precio_Bajo
Apple 150 10 20 5
Xiaomi 15 120 10 10
Samsung 30 15 140 20
Alcatel 5 15 5 160knitr::asis_output("#### Prueba ChiSquare")chisq=chisq.test(tabla_coches)
chisq
Pearson's Chi-squared test
data: tabla_coches
X-squared = 1836.3, df = 25, p-value < 2.2e-16knitr::asis_output("#### Residuos estandarizados ajustados")chisq$stdres Seguridad_Familiar Espiritu_Aventurero Lujo_Clasico
Volvo 16.4849524 -4.3363212 -3.5157437
Jeep -5.0011860 29.0754849 -5.8078773
BMW -2.7454331 -5.4051382 7.4748601
Mercedes -1.2561828 -6.4261504 8.7046388
Toyota -3.1762068 -3.3158126 -6.7953926
Tesla -4.3557352 -5.4051382 -2.5306736
Rendimiento_Deportivo Fiabilidad_Practica Innovacion_Sostenible
Volvo -4.9703933 0.1492051 -3.7121349
Jeep -1.5399995 -5.3355538 -5.6610144
BMW 7.6843198 -6.4250165 -2.2817900
Mercedes -0.2854976 -3.4046654 0.6360908
Toyota -5.4447114 22.7547844 -3.9390508
Tesla 2.9812077 -4.8573125 13.0137255knitr::asis_output("#### Análisis de correspondencias")# Realizar el análisis de correspondencias
# Realizar el análisis de correspondencias
ca_coches <- ca(tabla_coches)
# Resumen del análisis
print(summary(ca_coches))$scree
values values2 values3
[1,] 1 0.46785260 46.624981 46.62498
[2,] 2 0.30905460 30.799583 77.42456
[3,] 3 0.14610802 14.560747 91.98531
[4,] 4 0.06967519 6.943649 98.92896
[5,] 5 0.01074722 1.071040 100.00000
$rows
name mass qlt inr k=1 cor ctr k=2 cor ctr
1 Volv 158 163 132 -270 88 25 -251 76 32
2 Jeep 123 1000 408 1825 1000 875 -6 0 0
3 BMW 197 665 72 -213 124 19 444 540 126
4 Mrcd 199 692 47 -302 387 39 268 305 46
5 Toyt 126 926 249 -249 31 17 -1332 895 722
6 Tesl 197 370 93 -244 126 25 340 244 74
$columns
name mass qlt inr k=1 cor ctr k=2 cor ctr
1 Sg_F 158 115 129 -280 96 27 -127 20 8
2 Es_A 107 999 412 1968 998 882 -69 1 2
3 Lj_C 216 646 82 -261 180 32 420 466 123
4 Rn_D 169 676 47 -67 16 2 428 660 100
5 Fb_P 169 948 244 -277 53 28 -1137 895 708
6 In_S 180 370 87 -280 163 30 315 206 58
attr(,"class")
[1] "summary.ca"# Visualización del mapa perceptual
fviz_ca_biplot(
ca_coches,
repel = TRUE,
ggtheme = ggthemes::theme_economist(),
title = "Mapa del sector automóvil"
) +
labs(subtitle = "Basado en asociaciones de estilo de vida y valores")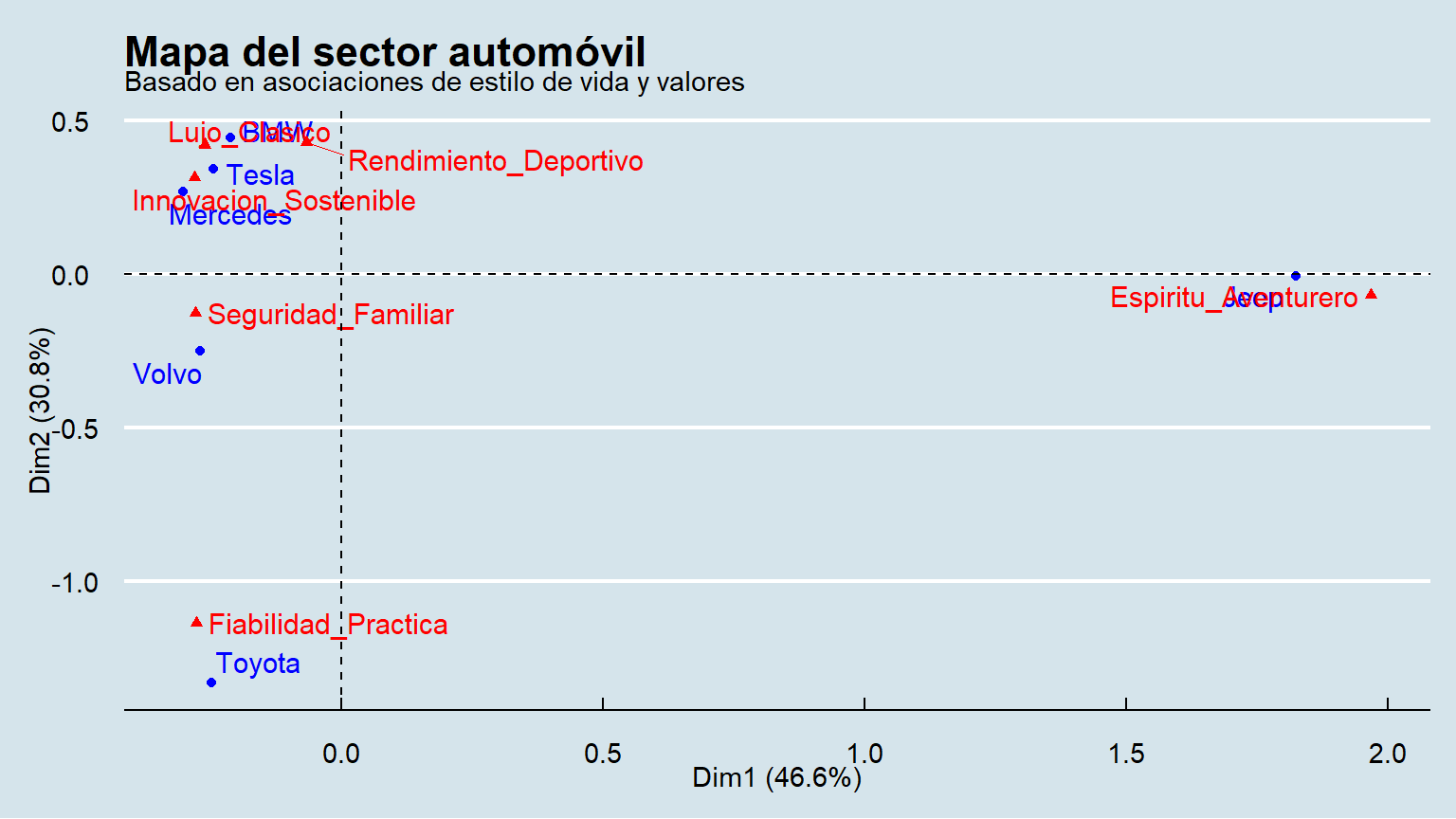
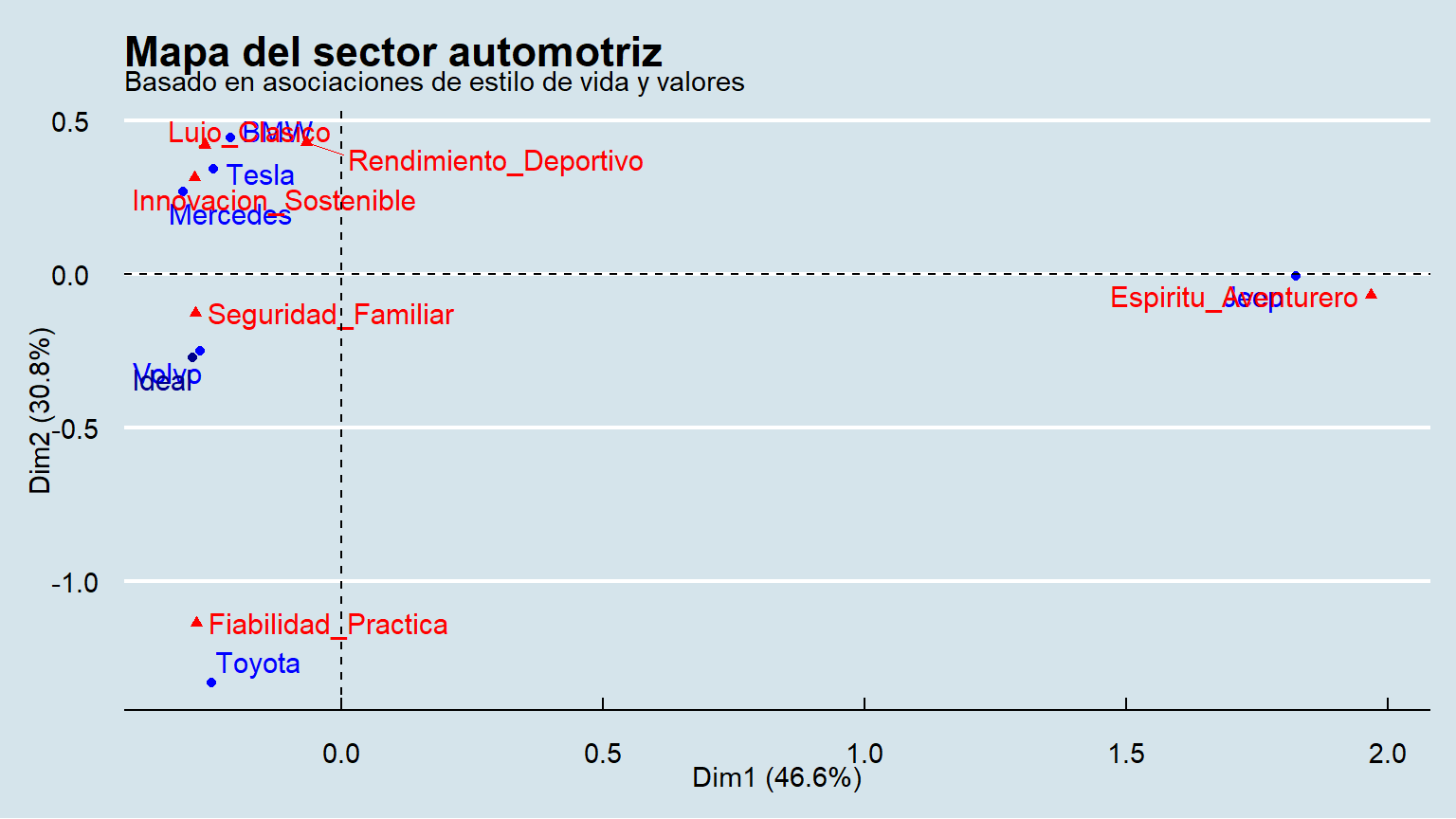
Análisis de la inercia: Aquí, las dos primeras dimensiones explicarán un porcentaje menor que en el caso 1 (quizás entre 70-85%). Esto es una lección importante: en mercados más complejos, un mapa 2D es una simplificación útil, pero no cuenta toda la historia. Hay más matices.
Interpretación de los ejes (aquí se necesita la “literatura”):
Fiabilidad_Practica (Toyota) y en el otro un cúmulo de atributos como Lujo_Clasico, Rendimiento_Deportivo (BMW, Mercedes). Este eje puede interpretarse usando la teoría de la motivación del consumidor: “Eje utilitario vs. hedonista/simbólico”. A la izquierda está la compra racional y funcional; a la derecha, la compra emocional, aspiracional y de autoexpresión.Seguridad_Familiar (Volvo) y en el otro Espiritu_Aventurero (Jeep). Este eje habla de valores más profundos: “Eje de responsabilidad/comunidad vs. libertad/individualismo”. Representa la tensión entre el arquetipo del “Cuidador” (Volvo) y el del “Explorador” (Jeep).Posicionamiento y competencia (contando la historia):
Rendimiento_Deportivo, mientras que Mercedes se asocia más con Lujo_Clasico. Compiten por el arquetipo del “Gobernante”, pero con matices.Innovacion_Sostenible. Atrae al arquetipo del “Mago” o el “Creador”. Tesla ha creado un nuevo sub-segmento de lujo basado en la tecnología y la conciencia ecológica, un verdadero océano azul.Conclusión del caso 2: El mercado automotriz no se define por un solo eje de competencia, sino por múltiples tensiones de valores. Mientras algunas marcas compiten ferozmente en territorios establecidos (lujo tradicional), otras han logrado crear y dominar nichos basados en arquetipos de estilo de vida (Volvo, Jeep) o han redefinido el mercado por completo (Tesla).
Introducimos ahora una fila “Ideal”, con un perfil promedio.
# --- CASO 2: MARCAS DE COCHES (COMPLEJO) ---
# Crear la tabla de contingencia
# Datos diseñados con más matices y solapamientos
datos_coches <- matrix(
c(
# Atributos -> Seguridad, Aventura, Lujo, Rendimiento, Fiabilidad, Innovación
140,
10,
40,
20,
50,
30, # Volvo
10,
150,
15,
30,
10,
10, # Jeep
40,
10,
130,
110,
20,
50, # BMW
50,
5,
140,
60,
40,
70, # Mercedes
20,
10,
10,
10,
160,
20, # Toyota
30,
10,
60,
80,
30,
150, # Tesla
100,
5,
5,
100,
100,
75 # Ideal
),
nrow = 7,
byrow = TRUE
)
# Asignar nombres
rownames(datos_coches) <- c(
"Volvo",
"Jeep",
"BMW",
"Mercedes",
"Toyota",
"Tesla",
"Ideal"
)
colnames(datos_coches) <- c(
"Seguridad_Familiar",
"Espiritu_Aventurero",
"Lujo_Clasico",
"Rendimiento_Deportivo",
"Fiabilidad_Practica",
"Innovacion_Sostenible"
)
# Convertir a tabla
tabla_coches <- as.table(datos_coches)
knitr::asis_output("#### Tabla de contingencia: Marcas de coches")Y lanzamos de nuevo el análisis. Este no se ve modificado, pero sí se calculan las nuevas coordenadas en el mapa para el punto “Ideal”.
print(tabla_coches) Seguridad_Familiar Espiritu_Aventurero Lujo_Clasico
Volvo 140 10 40
Jeep 10 150 15
BMW 40 10 130
Mercedes 50 5 140
Toyota 20 10 10
Tesla 30 10 60
Ideal 100 5 5
Rendimiento_Deportivo Fiabilidad_Practica Innovacion_Sostenible
Volvo 20 50 30
Jeep 30 10 10
BMW 110 20 50
Mercedes 60 40 70
Toyota 10 160 20
Tesla 80 30 150
Ideal 100 100 75# Realizar el análisis de correspondencias
ca_coches <- ca(tabla_coches, suprow = 7)
# Resumen del análisis
print(summary(ca_coches))$scree
values values2 values3
[1,] 1 0.46785260 46.624981 46.62498
[2,] 2 0.30905460 30.799583 77.42456
[3,] 3 0.14610802 14.560747 91.98531
[4,] 4 0.06967519 6.943649 98.92896
[5,] 5 0.01074722 1.071040 100.00000
$rows
name mass qlt inr k=1 cor ctr k=2 cor ctr
1 Volv 158 163 132 -270 88 25 -251 76 32
2 Jeep 123 1000 408 1825 1000 875 -6 0 0
3 BMW 197 665 72 -213 124 19 444 540 126
4 Mrcd 199 692 47 -302 387 39 268 305 46
5 Toyt 126 926 249 -249 31 17 -1332 895 722
6 Tesl 197 370 93 -244 126 25 340 244 74
7 (*)Idel NA 356 NA -285 186 NA -272 170 NA
$columns
name mass qlt inr k=1 cor ctr k=2 cor ctr
1 Sg_F 158 115 129 -280 96 27 -127 20 8
2 Es_A 107 999 412 1968 998 882 -69 1 2
3 Lj_C 216 646 82 -261 180 32 420 466 123
4 Rn_D 169 676 47 -67 16 2 428 660 100
5 Fb_P 169 948 244 -277 53 28 -1137 895 708
6 In_S 180 370 87 -280 163 30 315 206 58
attr(,"class")
[1] "summary.ca"El mapa ahora ya muestra el resultado de la inclusión del perfil “Ideal”.
# Visualización del mapa perceptual
fviz_ca_biplot(
ca_coches,
repel = TRUE,
ggtheme = ggthemes::theme_economist(),
title = "Mapa del sector automotriz"
) +
labs(subtitle = "Basado en asociaciones de estilo de vida y valores")